今年もあとちょっとですね。
ブログを見てくださった方や、コメントくださった方、皆さん本当に有難うございました!
まだ今年も更新するかもしれませんが、来年もよろしくお願いします!
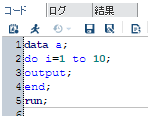
とりあえず、一度使ってみたかったEXPLODEプロシジャで締めたいと思います。
| filename ft15f001 temp; proc explode; parmcards; 1 HAVE A GREAT 2 NEW YEAR!! ; run;  |
。。。SAS Studioだと、結果がでないので、
| filename ft15f001 temp; proc explode; parmcards; 1 HAVE A GREAT 2 NEW YEAR!! ; run; |

| * EXCELを起動 ; options noxwait noxsync; %sysexec "C:\TEST.xlsx"; * 10秒待機 ; data _NULL_; rc = sleep(10,1); run; * EXCELデータを読み込む ; filename EXC dde "Excel|[test.xlsx]Sheet1!C1:C4"; data OUT1; attrib A length=8. B length=$20. C length=8. informat=yymmdd10. format=yymmdds10. D length=8. informat=time5. format=time5. ; /* filenameで読み込む行のみを設定した場合、firstobsオプションは不要 */ infile EXC notab dlm="09"x dsd missover lrecl=50000 firstobs=2; input A B C D; run; * ファイル参照を解放 ; filename EXC clear; OUT1
|
options noxwait noxsync;
%sysexec "C:\TEST.xlsx"; |
data _NULL_;
rc = sleep(10,1); run; |
filename EXC dde "Excel|[test.xlsx]Sheet1!C1:C4";
|
data OUT1; attrib A length=8. B length=$20. C length=8. informat=yymmdd10. format=yymmdds10. D length=8. informat=time5. format=time5. ; /* filenameで読み込む行のみを設定した場合、firstobsオプションは不要 */
infile EXC notab dlm="09"x dsd missover lrecl=50000 firstobs=2; input A B C D; run; |


IMAGE( file: "画像ファイルのフルパス" )
|
data _NULL_;
dcl odsout ob();
ob.image( file: "画像ファイルのパス\flower.jpg" ); run; 結果  |
| DHMS( 日付値, 時, 分, 秒 ) |
| data DT1; format DT yymmdd10. H M S 8. DTM e8601dt19.; * 日付値 ; DT = input("2014/01/10", yymmdd10.); * 時 ; H = 20; * 分 ; M = 10; * 秒 ; S = 00; * 日時値を作成 ; DTM = dhms(DT, H, M, S); run;
|
| DHMS( 日付値, 0, 0, 時間値 ) |
| data DT1; format DT yymmdd10. TM time5. DTM e8601dt19.; * 日付値 ; DT = input("2014/01/10", yymmdd10.); * 時間値 ; TM = input("20:10", time5.); * 日時値を作成 ; DTM = dhms(DT, 0, 0, TM); run;
|
PAGE()
|
data _NULL_;
dcl odsout ob();
*** 1ページ目 ; ob.table_start(); ob.row_start(); ob.format_cell( data:"aa" ); ob.row_end(); ob.table_end(); ob.page(); *** 2ページ目 ; ob.table_start(); ob.row_start(); ob.format_cell( data:"bb" ); ob.row_end(); ob.table_end(); run; 結果  |
LABEL, LENGTH などの変数属性を、まとめて定義できるステートメント。
データステップの一番先頭に書くと、ATTRIBに指定した順番で変数が並んでくれる。 |
*** 適当なサンプルデータ作成 ;
data DT1; retain A B C D E F 1 G "aa" H '20:00't ; run;
*** 要る変数だけ属性定義してKEEPする例 ; data OUT1; attrib A label="あ" length=8. B label="い" length=8. C label="う" length=8. G label="え" length=$10. H label="お" length=8. format=time5. ; set DT1; keep A B C G H; run;
|
keep A -- H ;
|
ods html close; ods pdf file="出力するファイルのパス\test.pdf"; data _NULL_; dcl odsout ob(); * レイアウト設定開始 ; ob.layout_absolute(); * 1個目の表を配置 ; ob.region( x:'1cm', y:'1cm' ); ob.table_start(); ob.row_start(); ob.format_cell(data:"aa"); ob.format_cell(data:"bb"); ob.row_end(); ob.table_end(); * 2個目の表を配置 ; ob.region( x:'5cm', y:'2cm' ); ob.table_start(); ob.row_start(); ob.format_cell(data:"cc"); ob.format_cell(data:"dd"); ob.row_end(); ob.table_end(); ob.layout_end(); run; ods pdf close; ods html;
結果  |
ods html close; ods pdf file="出力するPDFファイルのフルパス";
|
layout_absolute()
|
region( x : 'xの位置' , y : 'yの位置' )
|
layout_end()
|
ods pdf close; ods html; |
| *** Sample Data ;
data DT1;
input CODE$ NAME$; cards; 001 AAA 004 DDD 003 BBB 001 AAA 004 DDD 002 CCC 002 CCC ;
|
| proc freq data=DT1;
tables CODE * NAME / missing; format _all_;
run;  |
| proc freq data=DT1; tables CODE * NAME / missing list; format _all_; run;  |
data DT2; X=" AAA"; output; X="BBB"; output; run; proc freq data=DT2; tables X / missing list; format _all_; run;  |
| data DT1; format DT yymmdd10. TM time5.; DTM = input("2014/07/01 10:20:00", ymddttm.); * 日付値を抽出 ; DT = datepart( DTM ) ; * 時間値を抽出 ; TM = timepart( DTM ) ; keep DT TM; run;
|
| data DT1; A=1; B="AA"; output; A=2; B="BB"; output; run; data DT2; A=2; C=10; output; A=3; C=20; output; run;
DT2
|
| proc sql; create table DT3 as select coalesce( DT1.A, DT2.A ) as A , B , C from DT1 full join DT2 on DT1.A = DT2.A ; quit;
基本構文 from データセット1 full join データセット2 on 結合条件 解説 ① 結合時、2つのデータセットの全てのレコードを残します。 (結合条件に合うレコードだけでなく、片方のデータセットにしかないレコードも残す) ② 結合する2つのデータセットで同じ変数名を持っている場合、「データセット名.変数名」と書きます。 (今回の例では、DT1とDT2で同じ変数名Aを持っているので、どっちのAを使うのか明確にするため、「DT1.A」とか「DT2.A」と書いています) ③ SELECTでcoalesceという関数を使ってます。 この関数は、指定した引数の値を順番に見ていって、最初の非欠損値の値を返します。 つまりSELECTの「coalesce( DT1.A, DT2.A )」は、 ・DT1にしか存在しないレコードだったら、DT1.Aの値を持ってくる ・DT2にしか存在しないレコードだったら、DT2.Aの値を持ってくる という事をやっています。 |
| data DT1; length A $20. B C 8.; A="xxx"; B=1; C=2; run;
data DT2; length A C $10. D 8.; A="yyy"; C="zzz"; D=3; run;
|
| proc compare base=DT1(obs=0) compare=DT2(obs=0) listvar; run ; 結果の一部  |
| proc compare base=DT1 compare=DT2 listvar novalues ; run ; |